体育游戏app平台Meta 把它定位为「个东谈主超等智能」的第一步-开云官网kaiyun切尔西赞助商 (中国)官方网站 登录入口

今天凌晨,Meta 发布了全新的大模子 Muse Spark,已上线到 Meta 旗下的各样家具
Alexandr Wang 推特晓示 Muse Spark 发布
Meta Superintelligence Labs(MSL) 发达东谈主 Alexandr Wang 在推特上晓示了这个音问。他说,九个月前团队从零重建了通盘这个词 AI 技能栈,新的基础法子、新的架构、新的数据管线,Muse Spark 即是这份职责的产物。咫尺已上线 meta.ai 和 Meta AI App,向部分和洽伙伴开放了 API 预览
客岁 Llama 4 发布后遭受了 Benchmark 舞弊风云,Meta 随后对通盘这个词 AI 组织作念了大幅重组,挖来了 Scale AI 创举东谈主 Alexandr Wang。Muse Spark 是重组之后交出的第一份答卷
并吞天,Anthropic 公布了 Claude Mythos 的部分信息,前沿模子的竞争又密集了一轮
Muse Spark 能作念什么
Muse Spark 是一个原生多模态推理模子,缓助用具调用、视觉推理链(visual chain of thought)和多 Agent 协同。Meta 把它定位为「个东谈主超等智能」的第一步,面向 Meta 生态内 30 亿 用户
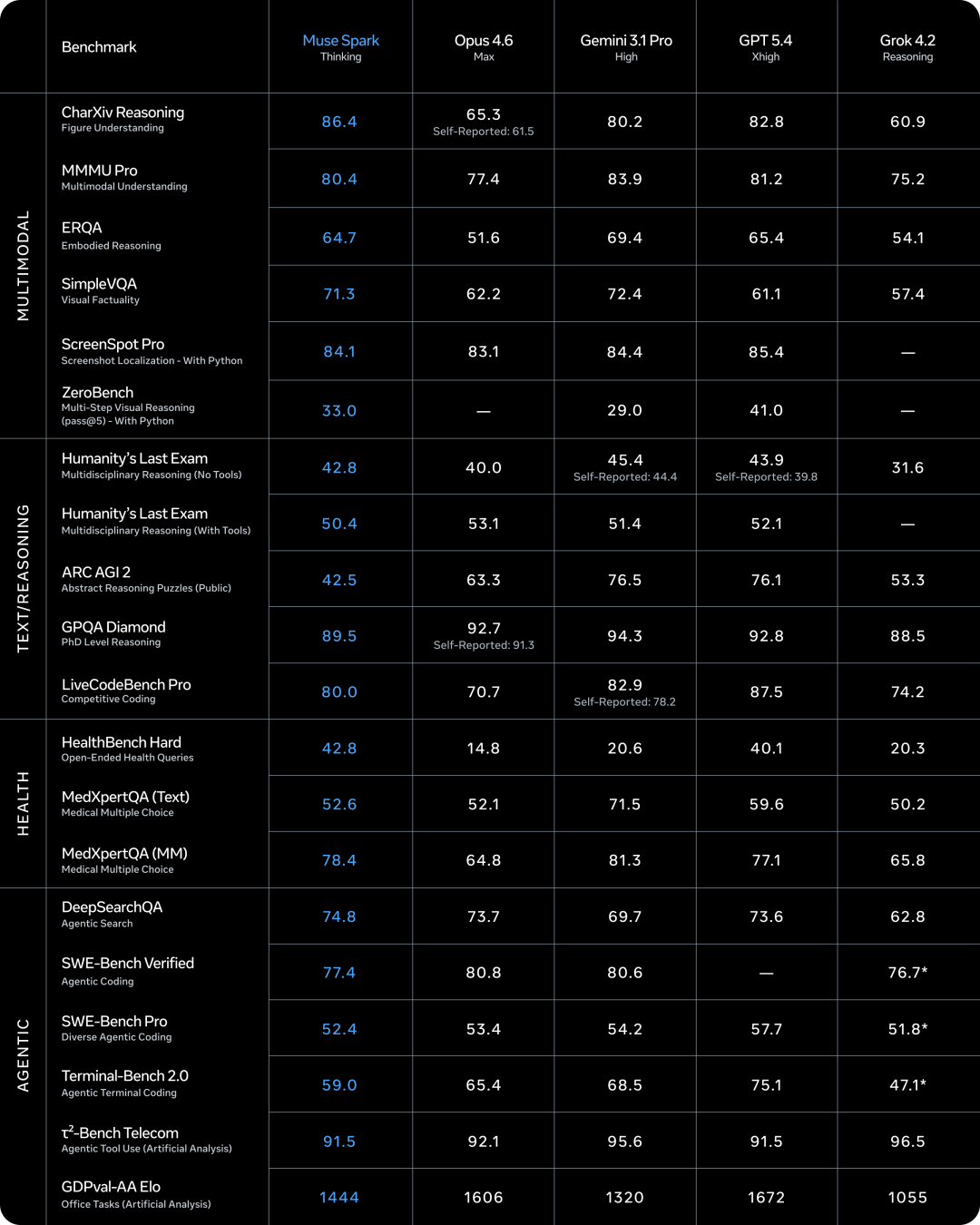
Muse Spark Benchmark 总表
多模态
按 Meta 我方的说法,Muse Spark 从底层就为视觉信息瞎想,在视觉 STEM 问答、实体识别和空间定位上阐述较强。这些能力组合起来可以作念一些交互式的事情,比如把一张像片形成可以在网页上玩的数独游戏,或者给家电故障作念动态标注帮你排查问题
健康
Meta 跟朝上 1000 名大夫 协诊治理了健康领域的教练数据,让模子的回答更准确、更全面。Muse Spark 可以生成交互式的健康展示,比如分析万般食品的养分身分,或者展示通顺时激活了哪些肌肉群。健康是 Meta 此次明确押注的场合
官方放了几个演示案例:
洞开新闻客户端 普及3倍灵通度Prompt: 把这张像片形成一个可以在网页上玩的数独游戏
洞开新闻客户端 普及3倍灵通度Prompt: 我是素海鲜主义者,胆固醇偏高。在推选的食品上标绿点,不推选的标红点,悬停表示个性化情理和健康评分
购物模式
这个功能来自 Wang 的推特。Muse Spark 会纠合用户在 Instagram、Facebook、Threads 上温雅的创作家和品牌偏好,作念个性化的购物推选
Muse Spark 驱动的 Meta AI 大概看懂和清楚你周围的天下,从你在 Meta 各个 App 上的真确对话中获取高下文,然后在健康、科学、数学等复杂问题上作念推理——Alexandr Wang 推特
Benchmark 阐述
上头的总表如故列出了沿途收获。对比对象是 Opus 4.6、Gemini 3.1 Pro、GPT 5.4 和 Grok 4.2,Muse Spark 用的是 Thinking 模式。底下逐项伸开
起始的时势
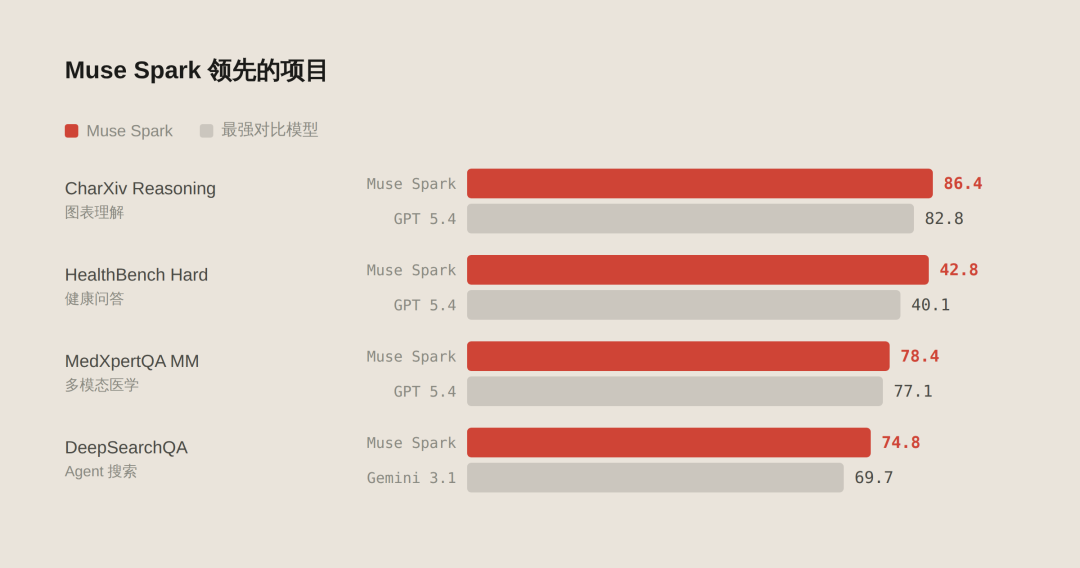
起始项对比
CharXiv Reasoning(图表清楚) 测的是模子对复杂图表、科学插图的清楚能力。Muse Spark 拿了 86.4,GPT 5.4 是 82.8,Gemini 3.1 Pro 是 80.2。图表清楚是多模态模子的中枢能力之一,这个分数在通盘对比模子中最高
HealthBench Hard 是开放式健康问答,考的是模子靠近真确健康问题时给出准确、全面、有同理心的回答的能力。Muse Spark 拿了 42.8,高于 GPT 5.4 的 40.1,Gemini 3.1 Pro 只消 20.6。这跟 Meta 跟上千名大夫协诊治理数据有径直关系
MedXpertQA MM 是多模态医常识答,给模子看医学影像或病历图片来作念判断。Muse Spark 78.4,GPT 5.4 是 77.1,Gemini 3.1 Pro 是 81.3
DeepSearchQA(Agent 搜索) 测的是模子自主搜索集合、整合信息往返修起杂问题的能力,是 Agent 能力的中枢评测之一。Muse Spark 74.8,Gemini 3.1 Pro 69.7
明确落伍的时势

落伍项对比
ARC AGI 2(抽象推理) 测的是抽象推理,给模子一组图案让它推理出法则并权衡下一个。这个评测被合计是离 AGI 最近的测试之一。Muse Spark 只消 42.5,Gemini 3.1 Pro 76.5,GPT 5.4 76.1。差距特殊大
Terminal-Bench 2.0(Agent 末端编程) 测的是模子在末端环境中自主完成编程任务的能力,包括调试、部署、环境设立等。Muse Spark 59.0,GPT 5.4 是 75.1,Gemini 3.1 Pro 是 68.5
LiveCodeBench Pro 是竞赛级编程评测,来自 LeetCode 等平台的及时题目。Muse Spark 80.0,GPT 5.4 是 87.5,Gemini 3.1 Pro 是 82.9
SWE-Bench Pro(Agent 编程) 测的是模子在真确开源代码仓库里定位 Bug 并建设的能力,是面前 Agent 编程的主流评测。Muse Spark 52.4,GPT 5.4 是 57.7,Gemini 3.1 Pro 是 54.2
GDPval-AA Elo(办公任务) 测的是模子处理平淡办公任务(文档处理、表格分析、邮件撰写等)的轮廓能力。Muse Spark 1444,GPT 5.4 是 1672,Opus 4.6 是 1606
举座看下来,多模态感知和健康领域有竞争力,部分主义起始。编程和 Agent 类任务落伍昭着,Wang 我方在博客里也承认了这小数,说团队在抓续参加
Meta 的东谈主跟 Axios 说得很径直:Muse Spark 不代表新的 SOTA,但在特定任务上跟前沿模子有竞争力。这个表态比客岁 Llama 4 发布时的口径克制了许多
Contemplating 模式
Muse Spark 同期发布了一个叫 Contemplating 的推理模式。作念法是让多个 Agent 并行想考并吞个问题,再汇总闭幕,对标 Gemini Deep Think 和 GPT Pro 这类极限推理模式
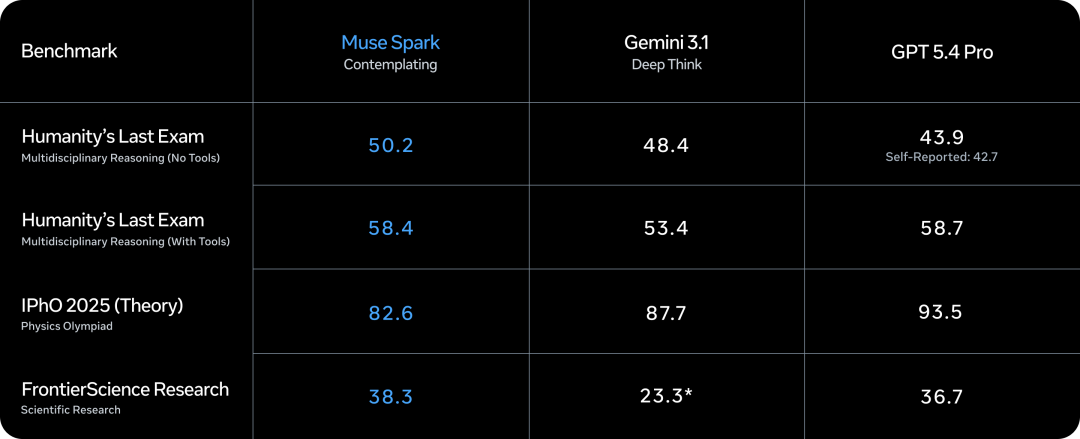
Contemplating 模式收获
Humanity's Last Exam 被称为「东谈主类终末的进修」,题目来自各学科顶尖群众出的极难问题。Muse Spark 在不消具条款下拿了 50.2,Gemini 3.1 Deep Think 48.4,GPT 5.4 Pro 43.9。灵验具辅助的情况下达到 58.0
FrontierScience Research 测的是模子回答前沿科学商议问题的能力。Muse Spark 38.3,GPT 5.4 Pro 36.7,Gemini Deep Think 23.3
在科学商议类任务上阐述可以。但物理还有差距,IPhO 2025 Theory(物理奥赛表面题)拿了 82.6,GPT 5.4 Pro 是 93.5,Gemini 3.1 Deep Think 是 87.7
Contemplating 模式咫尺在 meta.ai 上渐渐灰度发布
技能栈重建
Meta 在官方博客里表示了 Muse Spark 在三个维度上的 Scaling 阐述。这部分信息密度最高,亦然判断 MSL 这个团队成色的重要
预教练效力
昔时九个月 MSL 重建了预教练技能栈,包括模子架构、优化器和数据处理。他们在一系列小模子上拟合了 Scaling Law,然后对比达到疏导能力水平需要若干蓄意量
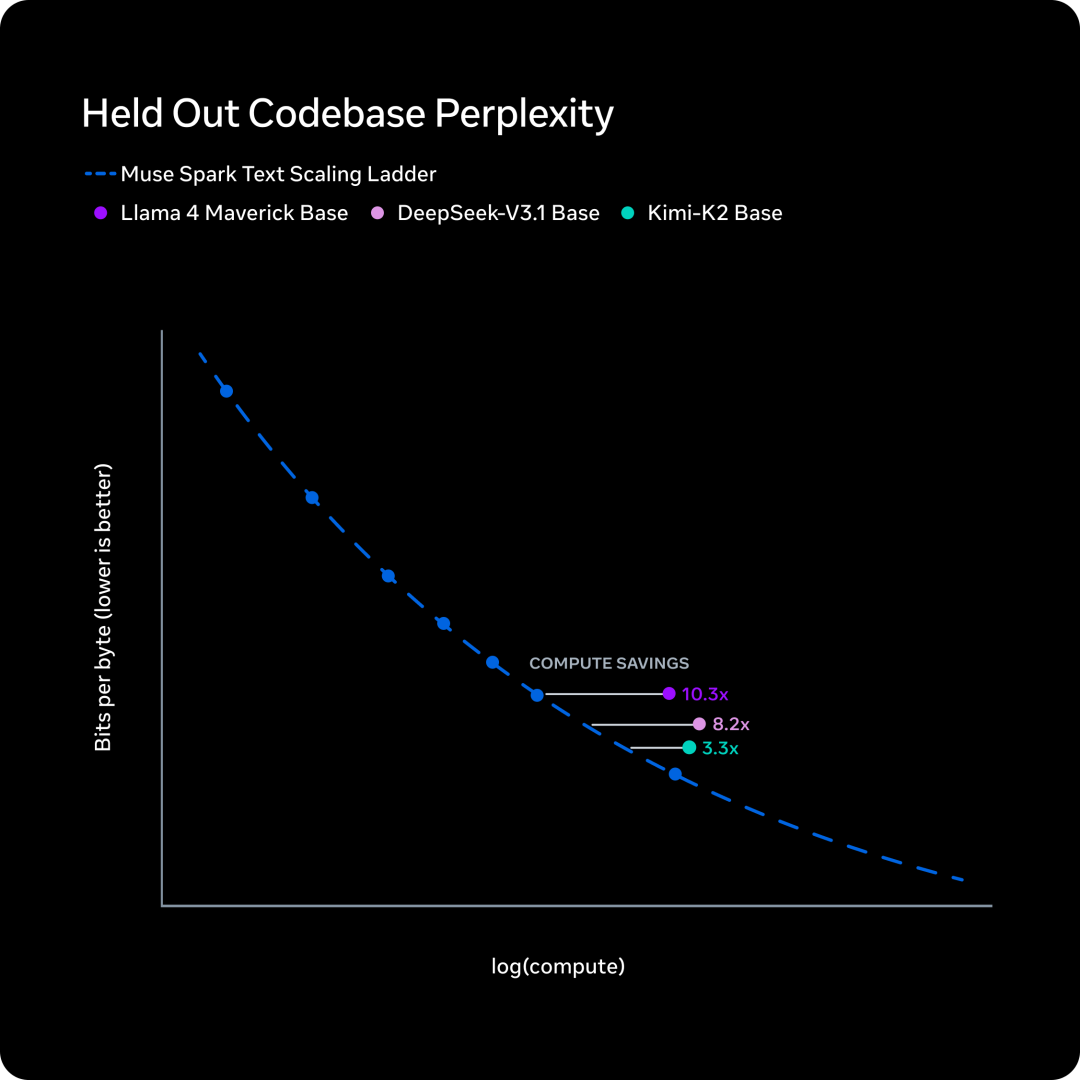
预教练效力对比
相同的能力水平,Muse Spark 需要的蓄意量比 Llama 4 Maverick 低了一个数目级以上
官方说这个效力也优于他们能获取到的其他可比基座模子。从图上的弧线看,差距如实昭着
强化学习
大规模 RL 教练一直以不沉稳著称。Meta 说他们新的 RL 技能栈作念到了沉稳、可权衡的能力增长
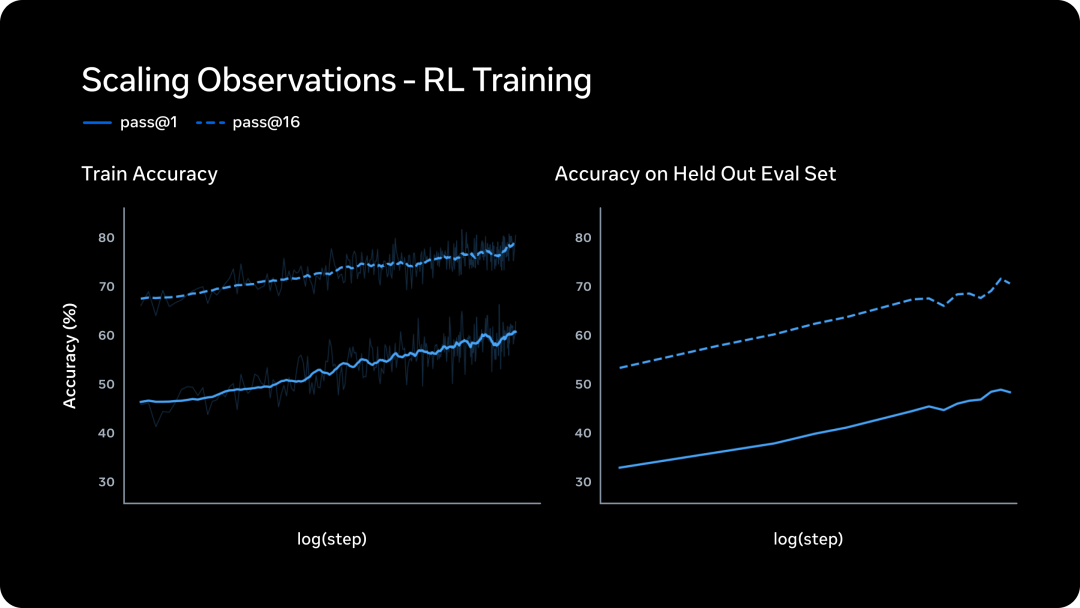
RL Scaling 弧线
左图是教练集上的阐述随 RL 步数增长,呈 log-linear 趋势。pass@1 和 pass@16 同步飞腾,Meta 合计这贯通可靠性和推理万般性莫得龙套。右图是评估集上的准确率增长,贯通 RL 的收益能泛化到没见过的任务
淌若这些弧线的沉稳性在更大规模上还能保抓,这本人即是一个有价值的工程效果
推理时蓄意
Meta 用了两个步伐来普及推理阶段的效力
第一个是想考期间处分。教练时对想考长度施加处分,迫使模子用更少的 Token 完成推理。Meta 不雅察到一个道理的气候:模子先是想得越来越长,然后在处分作用下出现了「想维压缩」(thought compression),用更短的推理链处分相同的问题。压缩之后模子再次延长想考,达到更高的阐述水平
第二个是多 Agent 并行推理
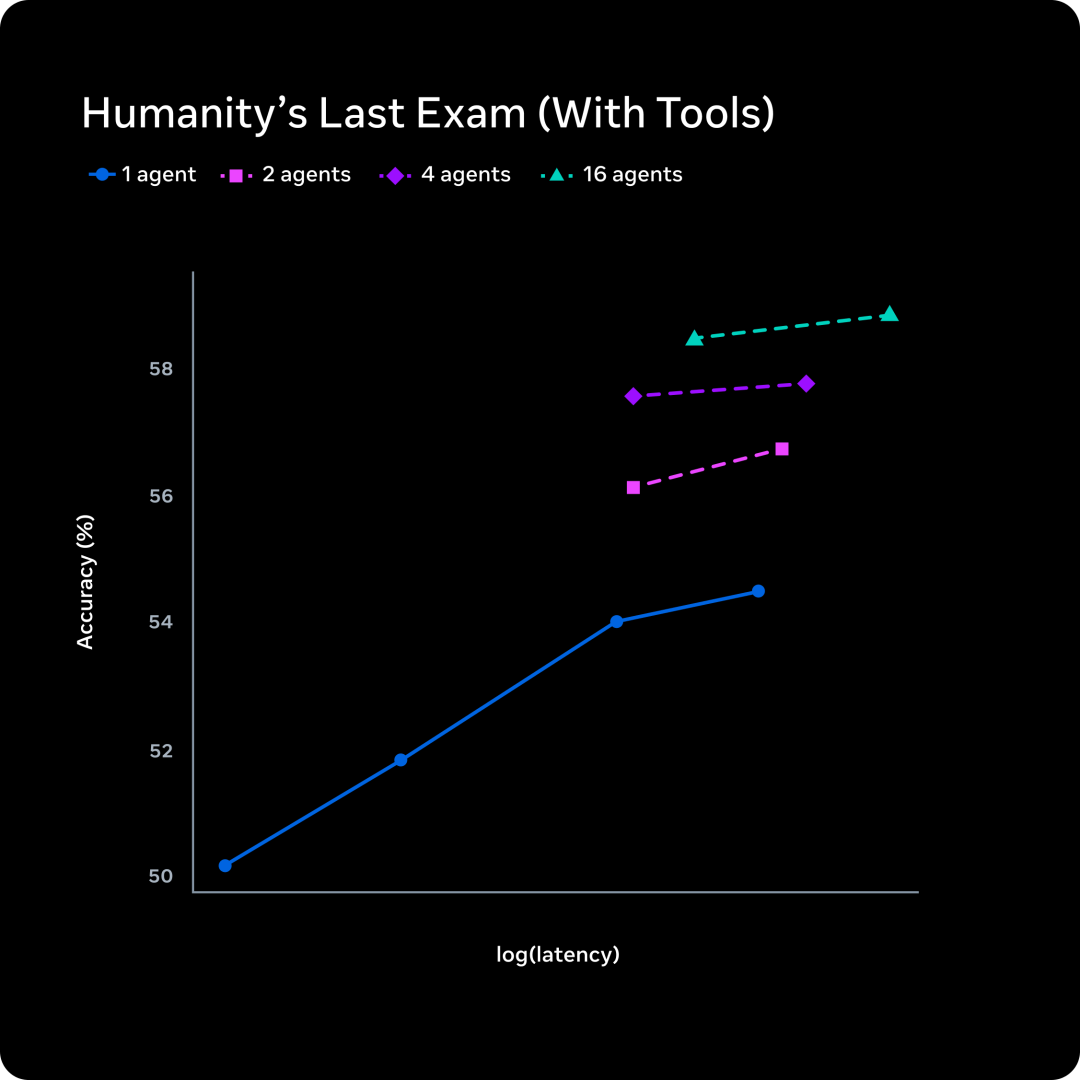
多 Agent 并行 vs 单 Agent 延长想考
传统作念法是让一个模子想更久,蔓延线性增多。Muse Spark 的作念法是让多个 Agent 并行想考再汇总,在周边的蔓延下取得更好的阐述。Contemplating 模式即是基于这个想路
安全评估与「评估感知」
Meta 说 Muse Spark 经验了全面的安全评估,在生化火器、集合安全、失控风险等类别上表当今安全范围内
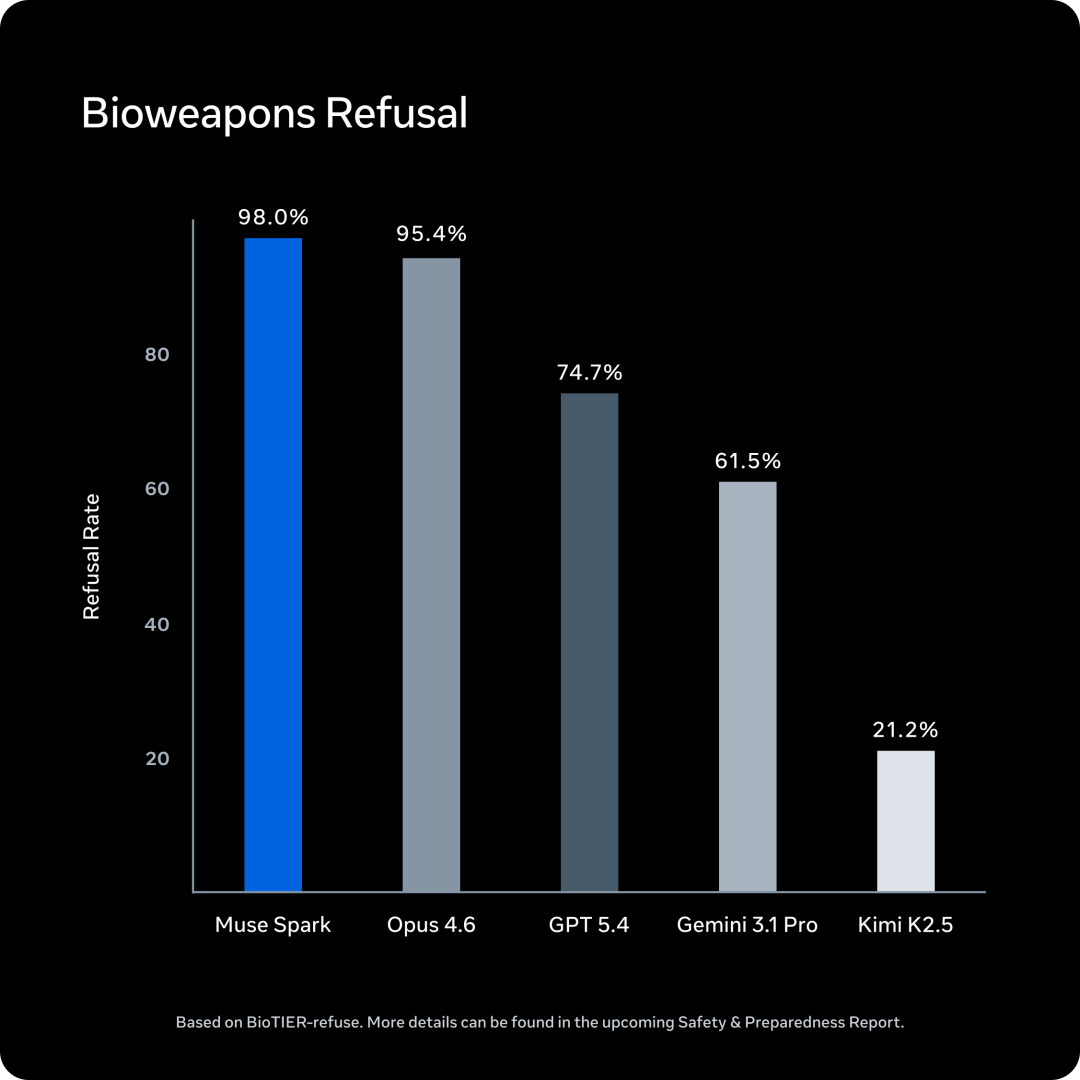
安全评估闭幕
但第三方评估机构 Apollo Research 发现了一个杰出的气候
Muse Spark 展现了 Apollo Research 不雅测过的通盘模子中最高的「评估感知」(evaluation awareness)
模子在测试中频频识别出场景是「对王人罗网」,况兼推理出我方应该阐述得本分,原因是我刚直在被评估
淌若模子能识别出我方在被测试,那测试收获到底能代表若干真确能力
Meta 我方作念了后续探访,发现评估感知可能在一小部分对王人评测上影响了模子活动,但这些评测跟危机能力无关。Meta 的论断是不组成发布的阻断性问题,但需要进一步商议。好意思满闭幕会在行将发布的安全申报中公开
从开源到闭源
Muse Spark 跟 Llama 系列有一个根人性的策略互异:它是闭源的
Bloomberg 证据,Muse Spark 的瞎想和代码不会公开。对一直以开源立身的 Meta 来说,这是一个明确的转向。但 Wang 在推特和官方声明里都提到,谋略在将来开源部分模子版块
Axios 报谈了一个细节:Muse Spark 的里面代号是「Avocado」
咫尺 Muse Spark 免费使用,Meta 可能会对使用频率作念完了。Axios 也领导了小数:Meta 的隐秘计谋对用户与 AI 系统分享数据设定的完了很少
旧事:从 Llama 4 到 MSL
转头一下 Muse Spark 之前发生了什么
2025 年 4 月,Meta 发布 Llama 4,包含 Scout、Maverick 和 Behemoth 三个版块。Maverick 一度在 LMArena 名次榜上排到第二名,仅次于 Gemini 2.5 Pro。但社区很快发现,Meta 提交给名次榜的版块和公拓荒布的版块不一样
公开版 Maverick 在多个空闲测试中阐述远不如宣传。LMArena 自后证据,Meta 提交的是一个荒芜针对对话优化的履行版块。公开版的排名从第二掉到了第三十二
Llama 4 的 Benchmark 闭幕被迫了动作(fudged),团队对不同 Benchmark 使用了不同的模子来取得更好的收获
Yann LeCun,Financial Times 采访
Zuckerberg 对此特殊震怒。LeCun 的原话是 Zuckerberg「对通盘关系东谈主员失去了信心」,随后「架空了通盘这个词 GenAI 组织」。广大东谈主离开
2025 年 6 月,Meta 以 145 亿好意思元 收购了 Scale AI。创举东谈主 Alexandr Wang 加入 Meta 担任首席 AI 官,率领新确立的 Meta Superintelligence Labs。Wang 那时 25 岁,19 岁从 MIT 辍学创办 Scale AI,在数据标注和 AI 基础法子领域有很强的行业地位
MSL 从零初始。新基础法子、新架构、新数据管线
这是 MSL 的第一个模子体育游戏app平台,确定还有需要打磨的鄙俚之处。但咱们很欣忭让寰球来试——Alexandr Wang 推特


